

Large Language Models (LLMs) have taken the world by storm. These AI systems can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. But with so many LLMs available, each with its own strengths and weaknesses, how do you choose the right one for the task?
The answer might surprise you: it’s about more than picking just one. Here’s why using multiple LLMs can be a powerful approach.
Leveraging 2 or 3 LLMs for a specific task can significantly enhance the quality and accuracy of the results. By leveraging multiple models, it becomes possible to cross-reference and validate the output, leading to a more robust and reliable outcome. This approach also allows for the strengths of each model to be utilized, compensating for any weaknesses present in a single model. Furthermore, employing different LLMs can provide a broader range of perspectives and knowledge, enriching the final result.
Pros
- Enhanced Accuracy and Reliability: No single LLM is perfect. It can make mistakes, misunderstand your intent, or generate factually incorrect outputs. By using multiple LLMs and comparing their responses, you can increase your results’ overall accuracy and reliability. Different LLMs are trained on various datasets and have different strengths. Combining their outputs can lead to a more comprehensive and nuanced understanding of the task.
- Reduced Bias: LLMs are trained on massive datasets of text and code, which can reflect the biases in the real world. Using multiple LLMs from different developers can help mitigate this issue. By incorporating a variety of perspectives, you can get a more balanced and unbiased output.
- Improved Creativity and Originality: Different LLMs have different styles and approaches to language. Combining their outputs can spark new ideas and create more creative and original content. Imagine using one LLM for factual information and another for a creative spin, creating a richer and more engaging experience. You can (also) use the same LLM but with different parameters (e.g., temperature, etc.’)
- Flexibility and Adaptability: Different tasks require different skills. Some LLMs excel at factual language tasks like summarizing information, while others shine at creative writing. Utilizing a multi-LLM approach, you can tailor your system to the specific needs of each project.
- Faster Processing and Completion: Some LLMs are faster than others. Distributing tasks across multiple LLMs allows you to speed up the overall processing time and get quicker results. This can be crucial in situations where real-time responses are essential.
Cons
- Increased Complexity: Managing and integrating multiple LLMs can be more complex than relying on a single system. You’ll need to consider factors like API access, cost management, and potential output inconsistencies. This is why I started this Multi-LLM-At-Once project. With one click, you can gain the results from two (and soon more) LLMs and compare them quickly and easily.
- Cost Considerations: Some LLMs have free tiers, while others require paid access. Using multiple LLMs can increase your overall costs. Carefully evaluate the costs and benefits before committing to a multi-LLM approach. This is the other reason I started the Multi-LLM-At-Once project – It allows you to work with these powerful LLMs for free. Soon, Meta is going to release Llama 3… It will be exciting to compare it to the other paid services.
The Multi-LLM project
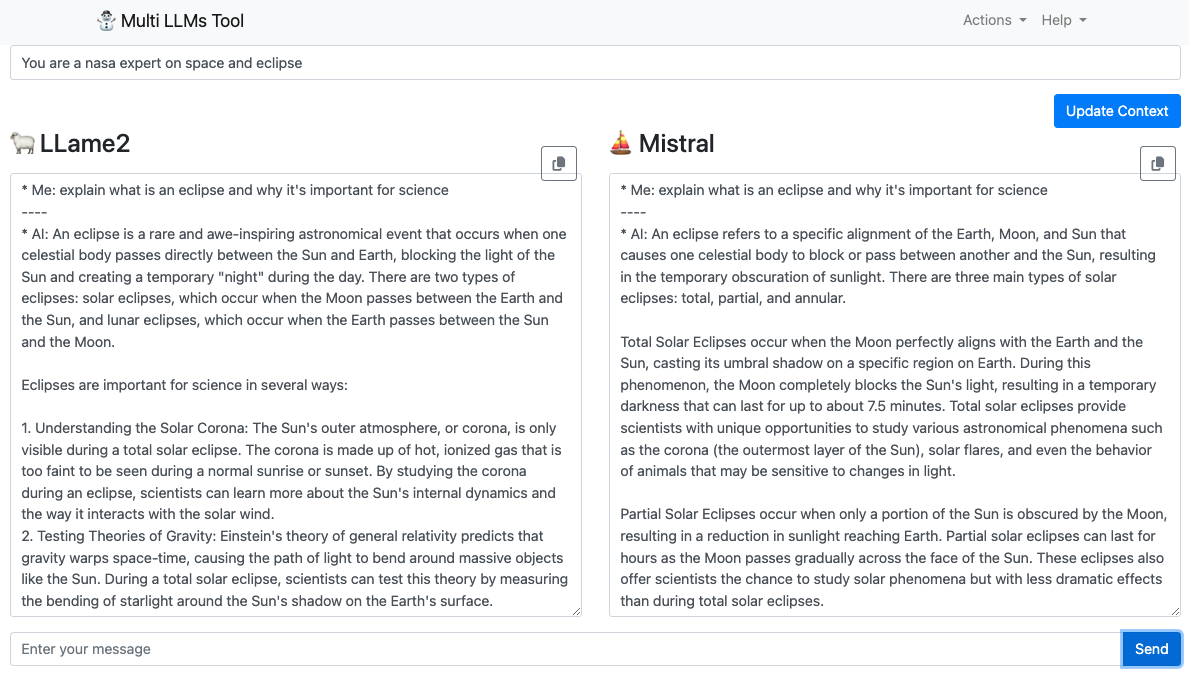
If you’re interested in exploring multi-LLMs’ power, I encourage you to check out my open-source project on GitHub. This project aims to develop a user-friendly platform that allows you to access and compare outputs from multiple LLMs for a single query.
Here are the models that are currently supported:
Here’s the table with ‘Pros’ and ‘Cons’ columns added, focusing on the top 3 aspects per model:
| Model | Parameters | Size | Download | Pros | Cons |
|---|---|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 | 1. Good general performance 2. Open source 3. Versatile | 1. Larger size 2. Potential biases 3. Limited domain knowledge |
| Mistral | 7B | 4.1GB | ollama run mistral | 1. Multilingual 2. Open source 3. Good general performance | 1. Larger size 2. Potential biases 3. Limited domain knowledge |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi | 1. Smaller size 2. Open source 3. Good general performance | 1. Potential biases 2. Limited domain knowledge 3. Slightly lower performance |
| Phi-2 | 2.7B | 1.7GB | ollama run phi | 1. Smaller size 2. Open source 3. Good general performance | 1. Potential biases 2. Limited domain knowledge 3. Slightly lower performance |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat | 1. Good for conversational tasks 2. Open source 3. Versatile | 1. Larger size 2. Potential biases 3. Limited domain knowledge |
| Starling | 7B | 4.1GB | ollama run starling-lm | 1. Good general performance 2. Open source 3. Versatile | 1. Larger size 2. Potential biases 3. Limited domain knowledge |
| Code Llama | 7B | 3.8GB | ollama run codellama | 1. Specialized for code 2. Good code generation 3. Open source | 1. Limited to coding tasks 2. Potential biases 3. Larger size |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored | 1. Good general performance 2. Open source 3. Versatile | 1. Larger size 2. Potential biases and offensive content 3. Limited domain knowledge |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b | 1. Higher performance 2. Open source 3. Versatile | 1. Very large size 2. Potential biases 3. Limited domain knowledge |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b | 1. Highest performance 2. Open source 3. Versatile | 1. Extremely large size 2. Potential biases 3. Limited domain knowledge |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini | 1. Smaller size 2. Open source 3. Good general performance | 1. Potential biases 2. Limited domain knowledge 3. Slightly lower performance |
| Vicuna | 7B | 3.8GB | ollama run vicuna | 1. Good general performance 2. Open source 3. Versatile | 1. Larger size 2. Potential biases 3. Limited domain knowledge |
| LLaVA | 7B | 4.5GB | ollama run llava | 1. Specialized for visual tasks 2. Open source 3. Good visual understanding | 1. Limited to visual tasks 2. Larger size 3. Potential biases |
| Gemma | 2B | 1.4GB | ollama run gemma:2b | 1. Very small size 2. Open source 3. Good general performance | 1. Potential biases 2. Limited domain knowledge 3. Lower performance |
| Gemma | 7B | 4.8GB | ollama run gemma:7b | 1. Good general performance 2. Open source 3. Versatile | 1. Larger size 2. Potential biases 3. Limited domain knowledge |
If you wish to read about other research that compare LLMs:
- More Agents Is All You Need and their code with the tasks.
- 🐺🐦⬛ Huge LLM Comparison/Test: 39 models tested (7B-70B + ChatGPT/GPT-4)
- Mistral LLM Comparison/Test: Instruct, OpenOrca, Dolphin, Zephyr and more
It’s a new era of AI-powered innovation.
It’s going to be interesting.
Discover more from Ido Green
Subscribe to get the latest posts sent to your email.
